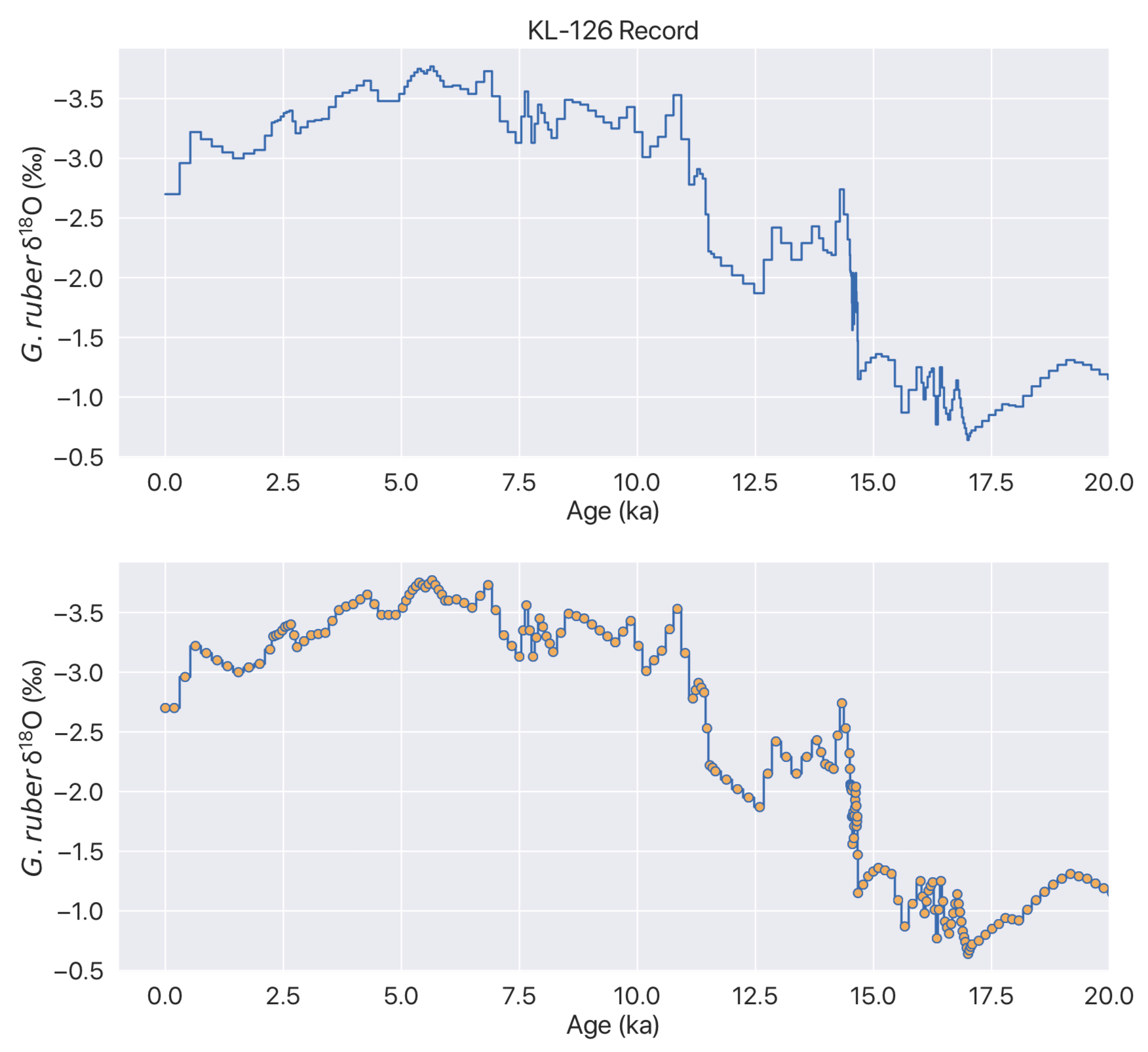
Transitioning from Papers 3 to Bookends: Part 1 - The Why
The Problem
Support for the desktop version of Papers 3, my erstwhile reference management software of choice, was discontinued and sales ceased last November. I have been using some version of Papers on the Mac and iOS for over seven years now, and I have really enjoyed using it on both platforms. The Papers app on iOS was especially useful, with its selective Dropbox-sync and night-reading features. Over the years however, there were many growing annoyances. The lack of significant updates was frustrating, and even when updates were offered, they were largely unable to keep up with operating system advances. Ever since Papers was bought over by ReadCube, I have been worried about the future direction of the software as well as the long-term durability of my reference management system.
Why a reference manager?
Considering the aforementioned problem, a fleeting thought I had was to archive/delete all of my 5000+ PDFs, save a BibTeX file, and give in to the constant connectivity of the attention-economy era: download PDFs from their source whenever I needed it. However, unlike what Spotify does for music (for me), after some thought, I realized that this approach would become troublesome when I’m in the field (>month downtime with no internet, etc.) or traveling. Furthermore, retrieving some hard-to-get PDFs or scans of papers I already would’ve been challenging. I wanted to have access to my papers.
How about simply keeping PDFs somewhere on my iCloud with a fixed naming convention and separately update a BibTeX file with reference information taken from Scholar? I knew I didn’t have to start from scratch because Papers 3 could generate one giant text file with all my references in BibTeX format. This approach was also not entirely appealing. I knew that such a strategy could become unwieldy real quick for an ever-increasing number of papers, especially if I wanted to go inside and edit some references along the way (something that always happens). Also, it would’ve been painful to generate a revised .bib file with a sub-selection of citations for particular projects. Finally, if I ever wanted to use Word or another WYSIWYG editor, citation management would’ve become… a chore. Considering today’s technological umbrella, I don’t think asking for a half-decent reference management software is a tall ask.
What would my ideal reference manager look like?
- Light, powerful, and not prone to crashing
- Ability to attach PDFs to references
- Transparent file handling and archival
- Ability to handle a LOT of PDFs
- Automatically “look” through a PDF and crawl the web for its full reference accurately
- Ability to generate bibliographies or list of references and citations in any format I wanted (preferably customizable)
- Have a PDF-editing interface where I can annotate or make notes on a paper
- Ability to batch processes the references of several PDFs
- Ability to have smart groups and smart search
- Ability to slice and dice my papers in any way I’d like (e.g., view by journal/authors/keywords, etc.)
- Syncs with cloud-service of choice (preferably iCloud so I can get out of the Dropbox ecosystem!)
- Preferably has its own app on iOS via cloud interface
- An affordable payment plan
Although Papers satisfied some of these constraints, as mentioned above, it had severe limitations, the most frustrating of which was its clunkiness and tendency to crash. Moreover, Papers3 used a “virtual library” system where you could choose how files would be named and stored and eventually viewed through its interface (e.g., Author-Year-Journal), but they were actually stored under a machine-readable format (long string of numbers; DDC3-VD2383248.pdf); I was never a fan of this opaque system.
Bookends
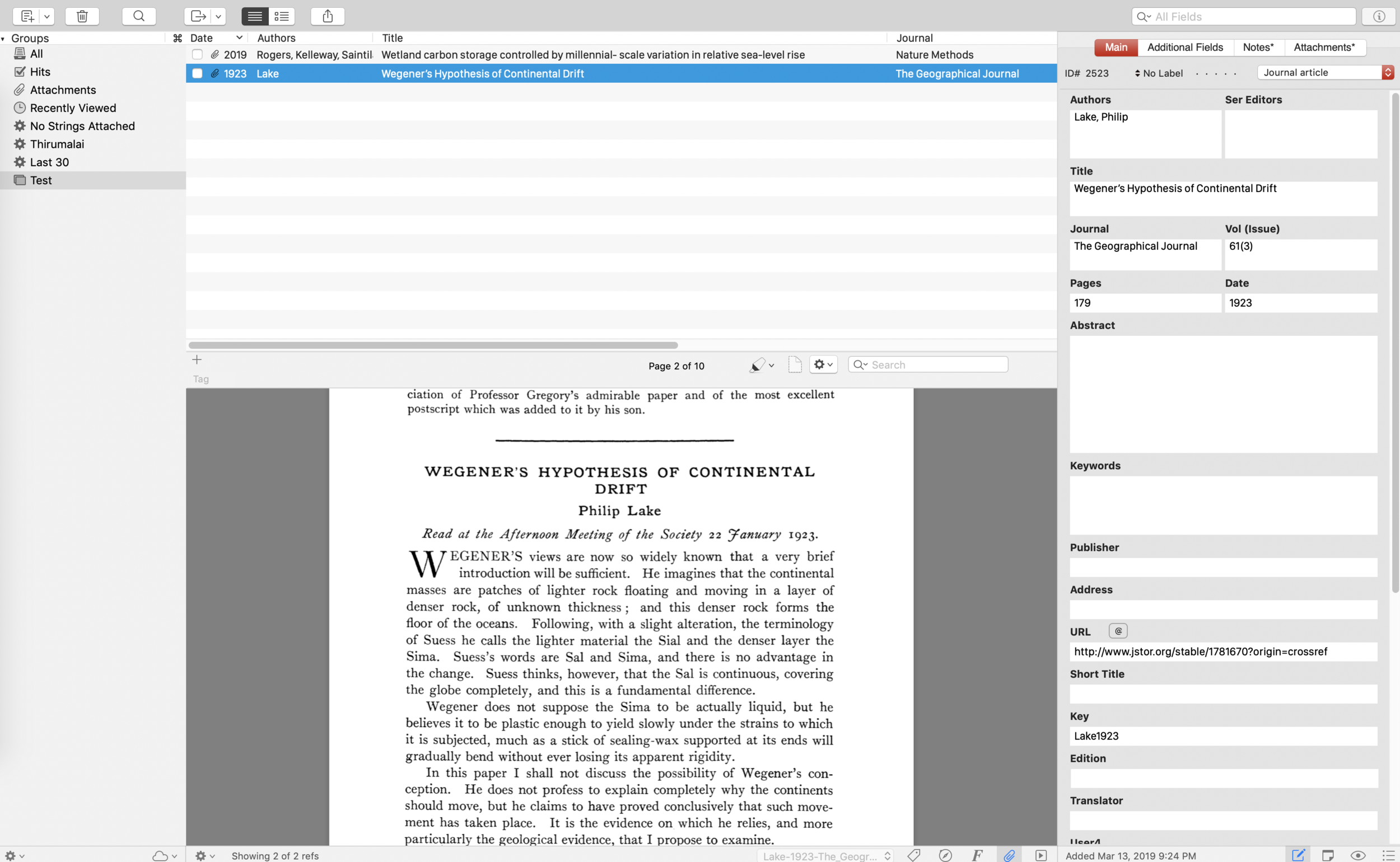
Enter Bookends from Sonny Software , a rather unassuming entrant compared to the more well-known platforms (Mendeley, Zotero, etc.) I had first heard of it through the MacPowerUsers forum and then saw some positive things about it on Twitter. Earlier this week, contemplating the long-term home of my PDFs, I decided to take the plunge and see what the fuss was about.
First off, Bookends on Mac costs $60 - it is a one-time buy with updates lasting for two years (at least). The iOS app costs $9.99 as a one-time buy, and then it is another $9.99/year for enabling cloud-sync. To me, this is a very reasonable pricing structure. Bookends does offer a free trial that limits you to 50 references so you can try it out. But first, is it worth it?

Let me start by saying that Bookends ticks off every bullet point that I mentioned above, and does a LOT more. Starting off, the first thing I did was to investigate how well it can capture a reference from a PDF — this seemed to go very smoothly — Bookends had no problem automatically retrieving information (via JSTOR/Scholar/Web of Life, etc.) for a recently published 2019 article or even one published in 1923.
Ok - so it can perform the basic functionality of a reference manager - what else? Well, the field entries to a reference were quickly editable (refreshingly no lag!), and there were many powerful options for global batch edits. More importantly, the citations’ and reference formats were completely customizable and so was the ability to rename PDF files after importing them. Furthermore, Bookends could sync using iCloud!
Oh my, this seemed rather promising at this point. But - what about iOS? This was where Papers3 excelled. Bookends on iOS did not disappoint. It seemed to be fast, light, and also could fully edit and export citations/references. There was functionality to use customizable search engines (Scholar/Web of Science etc.) for finding articles. Also, you could make notes, highlight, or annotate your PDFs, all of which would sync with the desktop version via iCloud. Furthermore, the app supported split screen view for drag and drop!
With this much potential, I decided to take the plunge. The real test was whether it would be able to handle my 5000+ PDFs and perhaps, even more, pressing: could it port all my existing citations from Papers?