The curious case of KL-126: Reconstructing “original measurements” from interpolated data
The Paper
In 2001, Kudrass and colleagues published a paper in Geology documenting a ~70,000 year record of Indian monsoon variability inferred from salinity reconstructions in a Bay of Bengal sediment core, SO93-KL-126. They measured the stable oxygen isotopic composition (δ¹⁸O) in shells of planktic foraminifer G. ruber. The δ¹⁸O of planktic foraminifera varies as a function of sea-surface temperature (SST) and the δ¹⁸O of seawater (δ¹⁸Osw). The latter term can be used as a proxy for salinity (how fresh or how saline past waters in the region were) and finally tied back to rainfall over the subcontinent, provided there is an independent temperature measurement. In this case, Kudrass and others also measured the concentration of alkenones in coeval sediments from core KL-126 as an independent temperature proxy. Thus, with these two measurements, they calculate the two unknowns: temperature and salinity. It is an important study with several implications for how we understand past monsoon changes. The study is ~18 yrs old and has been cited nearly 200 times.
The Problem(s)
One potential hurdle in calculating δ¹⁸Osw from KL-126 is that the δ¹⁸O and alkenone measurements have not been performed at the same time resolution i.e. not all δ¹⁸O values have a co-occurring alkenone-based SST value (the latter is lower-resolution). Such issues are common in paleoceanography due to sampling limitations and availability as well as the demands of intensive geochemical measurements, however, they can be overcome using statistical interpolation. Considering that the degrees of freedom in the SST time series is far less than the δ¹⁸O time series, to ensure that the calculated δ¹⁸Osw (and subsequently, salinity) doesn’t contain artifacts and isn’t aliased, the conservative approach is to interpolate the δ¹⁸O data at the time points where the (lower-resolution) alkenone measurements exist.
This is not the approach taken by Kudrass et al. in their study. Instead, they interpolate the alkenone measurements, with far less number of data points, to the same time steps as the δ¹⁸O measurements prior to calculating δ¹⁸Osw. Thus, the calculated salinity record mirrors the foraminiferal δ¹⁸O measurements because the alkenone SSTs do not vary all that much, and even when they do, are sampled at a much lower resolution.
This leads me to the main point of my blog post: I tried to re-calculate the KL-126 δ¹⁸Osw record, based on their actual number of measured data points - but there is another problem.
The KL-126 data is archived on PANGEA and when I investigated its contents, I found that (1) the alkenone data are archived based on the sample depth (without age) - a minor annoyance, meaning that one has to recalcluate their age model to place the alkenone data over time; but more importantly (2) the archived δ¹⁸O dataset contains >800 data points, sometimes, at time steps of nearly annual resolution! While this might be possible in high-sedimentation regions of the oceans, the Bay of Bengal is not anoxic, and thus, bioturbation and other post-depositional processes (esp. in such a dynamic region offshore the Ganges-Brahmaputra mouth) are bound to integrate (at least) years-to-decades worth of time. Moreover, when we take a closer look at the data (see below) we see multiple points on a monotonically increasing or decreasing tack - clear signs of interpolation - and in this case, a potential example of overfitting the underlying measurements.
Thus, the actual δ¹⁸O measurements from KL-126 have not been archived and instead only an interpolated version of the δ¹⁸O data exists (on PANGEA at least). Many studies have (not wholly correctly) used this interpolated dataset instead (I don’t blame them - it is what’s available!)
The Investigation
Here is a line plot of the archived δ¹⁸O dataset:

Figure 1. A line plot of the G. ruber δ¹⁸O record from KL-126, northern Bay of Bengal, spanning over the past 100 ka. Data is from that archived on PANGEA.
This looks exactly like Fig. 2 in the Geology paper. What’s the problem then? When we use a staircase line for the plot, or use markers, the problem becomes apparent:

Figure 2. Above: A staircase plot of the KL-126 δ¹⁸O record. Below: The same data plotted with markers at each archived data point. Note monotonically increasing or decreasing data points at several times over dataset.
A closer look, from 0-20 ka:
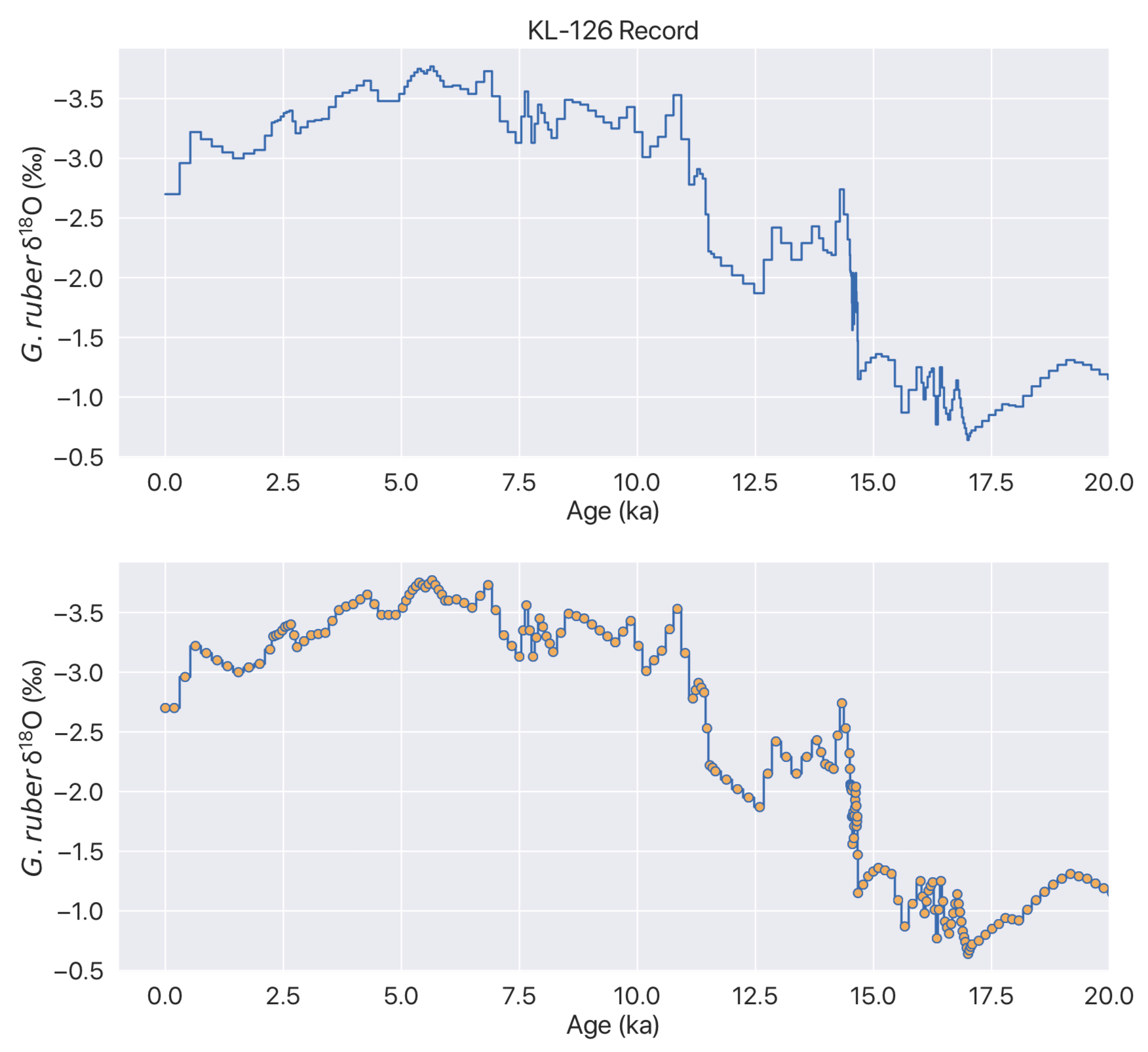
Figure 3. Same as in Fig. 2 but scaled over the last 20 ka.
Here is the time resolution of (using the first difference function) each data point with age:

Figure 4. Above: Staircase plot of the KL-126 δ¹⁸O record. Below: Time step (years) between δ¹⁸O data points in the archived record over time. Red dashed line depicts resolution of 50 years.
The Reconstruction
Now, let’s try to simulate the “original” data. With our eyes (or with, mine at least), we can “see” where they might have measurements, but how can we do this, objectively using data analysis techniques?
One way to approximate the original data is to use the findpeaks function (available in Python’s scipy OR the signal processing toolbox in MATLAB), which can grab local maxima or minima. This will enable us to ignore monotonoically increasing or decreasing interpolated data (by investigating where gradients become zero). Using this function, here are the simulated “original” measurements:

Figure 5. Finding local (note reversed δ¹⁸O scale) maxima (red) and minima (green) in the δ¹⁸O record.
Now, we can group all these ‘peaks’ and approximate the original dataset:

Figure 6. Reconstructing the original δ¹⁸O measurements in the KL-126 record. These data are found below.
It’s not perfect, but it’s not bad. I strongly feel that even this approximation is better than using a time series interpolated at a resolution (a lot) higher than the original measurements.
The Goods
If you’ve made it this far down in the blog post, perhaps you’d be interested in the simulated dataset for your own comparison as well as my code so you may check for errors etc. To save you the trouble, I’ve also added the Uk’37 dataset on the same age model so that an actual δ¹⁸O-seawater record over the appropriate time-steps can be calculated.
Here is a Jupyter notebook containing the Python code to replicate the plots and data anlysis from this post, as well as an Excel Spreadsheet containing the final, "reconstructed" dataset. It also contains steps for the alkenone interpolation.
KL-126 Record Archived on PANGEA (.txt)
Reconstructed KL-126 Record (.xlsx)
